optimizer 정리
optimizer는 Gradient descent로 w를 update할 때 사용하는 알고리즘으로, w 변화량을 구해 어느 방향/스텝사이즈로 나아가야 하는지 알려주는 알고리즘.
fine-tuning 단계에서 optimizer를 sgd, adam 등을 써보며 튜닝을 하는데,
optimizer 역사를 살펴보면 다음과 같다.
*Optimizer의 역사
- GD: 전체 데이터셋을 갖고 한발자국 전진할 때마다(learning rate) 최적의 값을 찾아 나간다
- 모든 데이터를 계산한다
- 최적의 한스텝을 나아간다
- -> 느리다
- SGD: 일부 데이터셋만을 갖고 최적의 값을 찾아 나간다
- 일부 데이터만 계산한다
- 빠르게 전진한다
- -> 그러나 최적의 값을 찾아가는 방향이 뒤죽박죽이고, local minimum에 빠질 위험이 있다.
- -> 또, step size를 잘 정하는 게 중요한데 이 step size를 잘 정하는 게 어렵다.

- 스텝 방향과 스텝 사이즈를 고려한 새로운 Optimizer들이 많이 나왔다.
- 스텝 방향성 고려: Momentum, NAG
- 스텝 사이즈 고려: Adagrad, RMSProp, AdaDelta
- 스텝 방향성 + 스텝사이즈 고려: Adam, Nadam

이제 학회나 현업에서는 Optimizer는 Adam을 쓰는 게 일종의 정설로 여겨진다.
하지만 왜 Optimizer로 Adam을 쓰는지 이런 질문을 받았고,
관련 질문들에 대해 생각해봤다.
Q. GD란 무엇인가?
전체 데이터셋을 갖고 한 발자국 전진할 때마다 최적의 값을 찾아 w를 update 해나가는 알고리즘
Q. GD의 문제점을 무엇인가?
1) local minimum에 빠질 위험
2) plateau 현상
3) zigzag 현상
Q. 왜 Optimizer를 쓰는가?
optimizer를 안 사용할 때는 1) local minimum에 빠질 위험 2) plateau 현상 3) zigzag 현상 이라는 문제가 있다.
즉, w가 계속 update 되어야 하는데, local minimum에 빠져서 더 이상 update 안 되는 현상이 일어나거나,
초기에는 좀더 빠른 step size로 나아가도 되는데 매우 느릿하게 update 되는 plateau 현상이 나타나거나,
w를 업데이트 하는 데 있어 원하는 방향으로 바로 업데이트 못하고 zigzag로 나아가는 현상이 나타난다.
optimizer는 이러한 문제점들을 해결해준다.
1) local minimum에 빠지는 위험을 해결해준다.
-> W가 1개인 모델에서 optimizer를 안 사용하면, w가 local minimum에 도달했을 때 더 이상 update 안 되는 문제가 있다.
2) plateau 현상을 해결해서 w를 업데이트 해준다.
-> epoch가 많이 들어간다. 즉, 학습 속도가 느리다.
3) weight space가 skewed된 gradient에 이러한 zigzag 현상을 해결해서 업데이트 해준다.
-> w를 찍어보면 w가 왔다갔다하며 update 되는데, 이를 일직선 방향으로 업데이트하도록 도와준다.
그렇다면 왜 adam을 쓸까? 사실 이제는 adam을 쓰는게 보편화되었지만
adam을 쓰는 이유를 물어본다면 다음과 같이 답할 것 같다.
Q. 왜 Optimizer로 Adam을 쓰는가?
GD를 update할 때 optimization하는 방식은 크게
1) 스텝 방향을 최대한 일직선으로 하거나,
2) 스텝 속도를 최대한 빠르게 하는 방식으로 발전해 왔는데,
adam은 스텝 방향과 스텝 속도 모두를 고려한 optimization 이다.
그래서 plateau 현상과 ziazag 현상을 모두 해결해주고,
따라서 zigzag 없이 일정한 방향으로 빠르게 나아갈 수 있다.
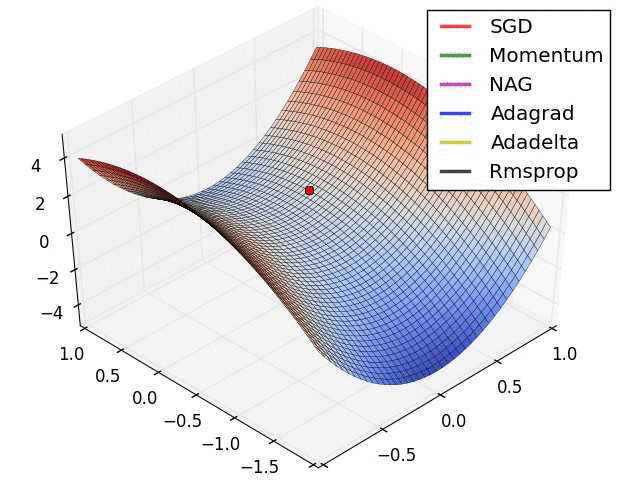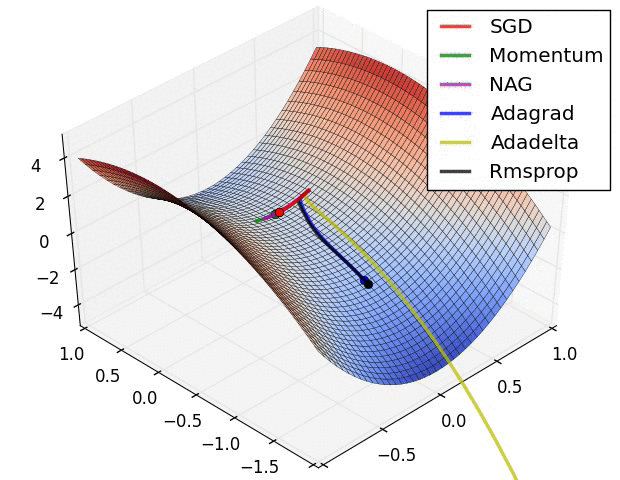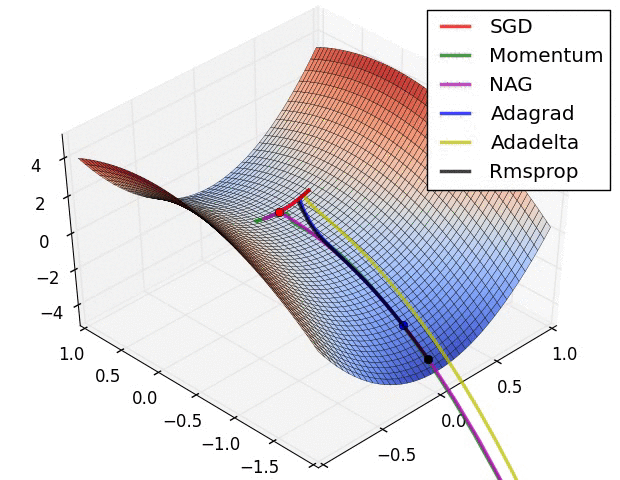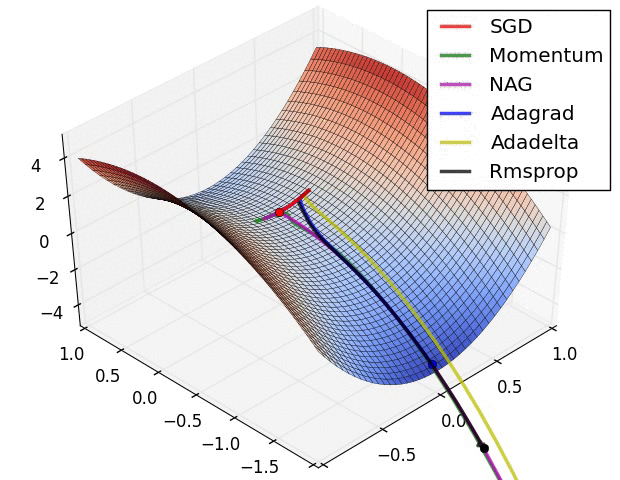
Q. 등고선이 굉장히 꼬여 있는 skewed된 상황에서 각 optimizer는 어떤 성능을 보이는가?
1) SGD - 앞으로 안 가는 수준....
2) Momentum, Nesterov Momentum (momentum 방식) - 가속도로 확 치고 올라오지만, 많이 휜다.
3) AdaGrad, RMSPROp (adaptive 방식) - 빠르진 않지만 zigzag 없이 일정한 방향을 유지하려 한다.
-참고문헌
11. Optimization - local optima / plateau / zigzag현상의 등장
지난시간까지는 weight 초기화하는 방법에 대해 배웠다. activation func에 따라 다른 weight초기화 방법을 썼었다. 그렇게 하면 Layer를 더 쌓더라도 activation value(output)의 평균과 표준편차가 일정하게 유
nittaku.tistory.com
딥러닝(Deep learning) 살펴보기 2탄
지난 포스트에 Deep learning 살펴보기 1탄을 통해 딥러닝의 개요와 뉴럴 네트워크, 그리고 Underfitting의 문제점과 해결방법에 관해 알아보았습니다. 그럼 오늘은 이어서 Deep learning에서 학습이 느린
seamless.tistory.com
jaejunyoo.blogspot.com/2017/05/marginal-value-of-adaptive-gradient-methods-in-ML.html
초짜 대학원생의 입장에서 이해하는 The Marginal Value of Adaptive Gradient Methods in Machine Learning (1)
Machine learning and research topics explained in beginner graduate's terms. 초짜 대학원생의 쉽게 풀어 설명하는 머신러닝
jaejunyoo.blogspot.com
'Artificial Intelligence' 카테고리의 다른 글
| train data / validation data / test data 차이 (0) | 2021.01.19 |
|---|---|
| 분석환경 requirements (0) | 2021.01.18 |
| conda 터미널 명령어 (0) | 2021.01.12 |
| numpy의 dot / matmul 차이 (0) | 2021.01.12 |
| [ADP, ADsP] 데이터 처리 순서: Legacy -> staging -> ODS -> DW -> DM -> R, SAS, PYTHON (0) | 2020.11.19 |

