Contents |
1. 최신 AI 논문 보는 곳
1) 분야별 최신 논문 볼 수 있는 사이트 - paperswithcode
Papers with Code - The Methods Corpus
982 methods • 54838 papers with code.
paperswithcode.com
2) 아직 학회에 발표되지는 않았지만 완전 최신 논문 볼 수 있는 사이트 - arxiv
Arxiv Sanity Preserver
arxiv-sanity.com
2. 모든 분야 논문 정리
1) Papers You Must Read - www.notion.so/c3b3474d18ef4304b23ea360367a5137?v=5d763ad5773f44eb950f49de7d7671bd
Papers You Must Read
Data Science & Business Analytics Lab School of Industrial Management Engineering Korea University Homepage: http://dsba.korea.ac.kr/ Youtube: https://www.youtube.com/channel/UCPq01cgCcEwhXl7BvcwIQyg Reading loadmap: https://www.dropbox.com/s/5x9u0rnsxos8q
www.notion.so
2) github.com/floodsung/Deep-Learning-Papers-Reading-Roadmap
floodsung/Deep-Learning-Papers-Reading-Roadmap
Deep Learning papers reading roadmap for anyone who are eager to learn this amazing tech! - floodsung/Deep-Learning-Papers-Reading-Roadmap
github.com
3) 책 "핸즈온 머신러닝 2판" - 2019년 책 pdf
CNN, NLP 등 각 분야 시작 논문부터~최신 논문 경향까지 설명하고 있는 책이기에, 전반적인 모든 분야에 대한 논문 요약을 보고 싶을 때 추천하는 책이다. 각 설명이 어떤 논문에서 나왔는지도 주석으로 달려 있기에 추가 공부를 하고 싶으면 해당 논문을 찾아볼 수 있다.
3. 분야별 논문
3.1. Computer Vision 논문
Computer Vision 분야의 주요 task는
1) image classification,
2) Single Classification & Localization & Detection,
3) Multiple Object Detection & Localization & Classification
이렇게 3가지로 나뉜다.
image classification으로 CNN을 처음 접하게 됐지만, 현업에서는 image classification을 하는 일은 거의 없는 것 같다. 이미 이쪽은 너무 좋은 모델들이 많아서 굳이 모델러의 손길이 필요한 것 같지 않다. 다만 현업의 데이터셋 특성 때문에 여전히 이미지 분류가 잘 안 되는 경우가 많은데, 가령 공장 이미지는 label이 잘못 저장되어 있거나, 사진 자체가 제각각 이상하게 찍혀서 분류를 하기가 힘들다는 데이터셋 상의 문제가 있다. 또, 사진 자체가 너무 부족하다거나! 그래서 image classification 쪽은 모델을 얼마나 잘 만드냐보다, relabeling, data augmentation이 더 많이 필요한 것 같다. 모델 자체는 정말 공부하다 보면 하나도 안 어렵다.
CNN의 또 다른 분야는 object detection이 있는데, single detection, multiple detection이 있다. 자율주행차, 쇼핑 등에 쓰여서 이 분야는 계속 성장할 것 같다.
1) Computer Vision 강의 - 논문으로 짚어보는 딥러닝의 맥 www.edwith.org/deeplearningchoi/joinLectures/10979
논문으로 짚어보는 딥러닝의 맥 강좌소개 : edwith
- 최성준
www.edwith.org
3.2. NLP 논문
NLP 분야는 ACL, EMNLP, NAACL 대표적인 Top Conference 학회에 속한다.
NLP의 하위 분야에는 음성 인식, 언어 이해, 대화 관리, 언어 생성, 음성 합성 등이 있다.
한국어 자체가 희소성 있는 언어에 속하다 보니까, 개인적인 생각으로는 한국어 자체에 대한 연구보다는
주로 기계번역(한글<->영어, 중국어 등), 음성 인식(음성->한글), 챗봇쪽으로 연구가 흘러가는 것 같다.
NLP 입문하기에는 "밑바닥부터 시작하는 딥러닝2"와 위키독스가 정말 좋다.
이 책 2권에는 통계적 모델부터 rnn, lstm, gru, transformer까지 설명되어 있는데
최신 NLP 논문 보기 전에 공부하기 좋은 책이다.
1) 책 "밑바닥부터 시작하는 딥러닝2"
통계적 모델, word2vec, rnn, lstm, gru, transformer 등에 대해 설명하고 있는 책
2) 온라인책 "딥러닝을 이용한 자연어 처리 입문" wikidocs.net/book/2155
위키독스
온라인 책을 제작 공유하는 플랫폼 서비스
wikidocs.net
3) 카카오브레인 NLP 깃헙 - github.com/kakaobrain/nlp-paper-reading
kakaobrain/nlp-paper-reading
Paper reading notes from Kakao Brain's NLP team. Contribute to kakaobrain/nlp-paper-reading development by creating an account on GitHub.
github.com
3.3. Recommendation 논문
추천시스템의 기본은 Content-based filtering, Collaborative filtering 이다.
Content-based filtering은 특정 아이템에 기반해 비슷한 아이템을 추천해주는 것으로,
유저가 어떤 아이템 A(호러, 무서움, 2019 등등)을 좋아하면 A와 속성이 비슷한 다른 아이템을 추천해주는 걸 말한다.
한편 Collaborative filtering은 사용자 그룹이 형성되어 있고, 그들의 평가점수와 선호도를 고려해서 나와 비슷한 다른 사용자가 선호하는 아이템을 추천해주는 것이다.
나와 유사한 아이템을 평소에 좋아했던 친구가 B라는 아이템도 선호한다면, 내게 B라는 아이템을 추천해주는 걸 말한다.
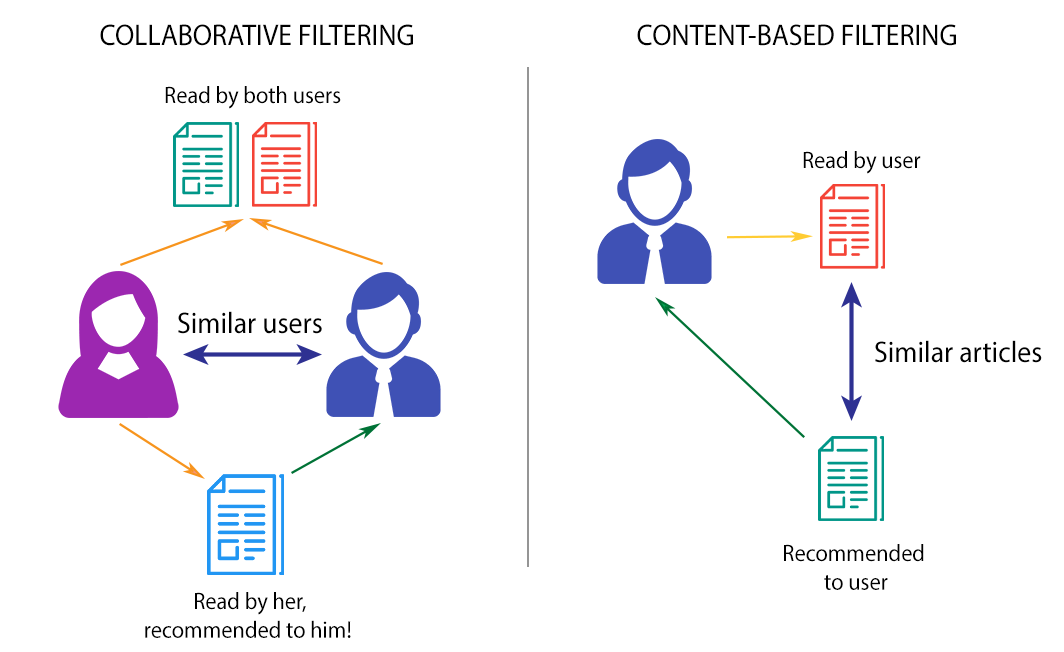
기본은 이 2가지인데, 각각의 문제점들이 있어서 hybrid해서 쓰거나,
최근에는 knowledge graph 기반 추천시스템이 더 핫한 것 같다.
각 아이템에 대한 속성을 graph로 표현하면 더 잘 나타낼 수 있다는 것도 있고,
특정 유저가 어떤 영화를 좋아한다고 했을 때, 감독 때문에 보는 건지, 배우 때문에 보는 건지 이런 것들을 더 세분화할 수 있어서 쓰이는 것 같다.
1) 추천시스템 강의 - github.com/choco9966/Recommendation-Tutorial?fbclid=IwAR3f4mKzU0c9pSouLAl4sHwOuiOqk9HVBKllJza6I_V44lQOh1Q1UhbKwwM
choco9966/Recommendation-Tutorial
Contribute to choco9966/Recommendation-Tutorial development by creating an account on GitHub.
github.com
3.4. Tabular data 논문
이 분야 논문은 그때그때 찾아보는 쪽에 가까워서 주기적으로 찾아보는 링크는 없지만,
주로 현업에서 일할 때 tabular data를 다루는 일이 많아서 정리해둔다.
tabular data를 다룰 경우 주로 task는
1) 상황 분석 2) 미래 예측 으로 나눠지는 것 같다.
상황 분석 같은 경우는, 어떤 현상이 일어날 때 그 현상이 왜 일어났는지 분석하는 쪽인데,
그래서 예측력이 좋은 복잡한 모델보다는, 설명력이 높은 모델들을 주로 쓴다.
decision tree나 linear/logistic regression, k-means clustering을 주로 쓰는 것 같다.
아니면 모델을 안 쓰고 단순 통계적 분석도 많이 쓰이는데, t-test, ANOVA, 상관분석 등도 많이 쓴다.
미래 예측 같은 경우는, 상황 분석이 끝나고 미래 예측까지 해보자 했을 때 주로 진행되는데,
이때 쓰는 모델은 몇 개로 정해져 있는 것 같지는 않지만,
complex 모델을 써도 모델에 대해 설명해야하는 경우가 많아서
주로 모델을 만들고 explainer를 붙이는 경우가 많은 것 같다.
즉, randomforest로 어떤 모델을 만들었다면, LIME 같은 explainer를 만들어서 모델이 어떤 변수, 구간에서 그러한 선택을 한 건지 추출한다.
굉장히 많은 competition이 tabular data에 대해서 열리는데,
모델은 xgboost나 lightgbm으로 종결되는 것 같다.
하지만 알고리즘을 어떻게 짜느냐,
feature enginnering을 어떻게 하느냐,
결측치가 있는 경우는 전처리를 어떻게 하냐에 따라 성능이 천차만별로 갈리는데,
tabular data 쪽은 그만큼 feature enginnering이나 null handling이 중요한 것 같다.
요일 컬럼으로부터 isHoliday 컬럼을 만든다든지, EDA나 통계적 기법을 통해서 중요한 feature들을 많이 만들고,
또 안정성을 확보하기 위해서 feature를 만들고 VIF 등을 써서 feature selection 작업을 거친다.
null handing이나 outlier handling도 중요한데, 빈 값이 많은 경우 여기서도 성능 차이가 갈린다.
근데 이 부분은 딱히 방법이 없는 것 같다. 그냥 계속 EDA를 하면서 규칙을 찾아서 넣는 수밖에 없는 것 같지만,
최근에 새로운 기법을 알게 됐는데 일단 lightgbm에 다 때려넣고 null이 있을 경우 random_seed를 특정 방향으로 잡아주고 fine-tuning으로 해결하는 방법도 있는 듯하다.
아무튼 tabular dataset을 다룰 때 주로 마주하는 이슈는,
1) null data handling / outlier handling
2) feature enginnering
3) evaluation metric (특히, imbalanced class 일 경우)
4) model algorithm (이진 분류를 먼저 하고 regression을 할지, dnn 등 여러 모델과 ensemble할지 등)
이렇게 4가지였던 것 같다.
대개 evaluation metric은 풀어야 하는 비즈니스 문제에 따라 정해지는 경우들이 많아서
100% 타임라인에서 90%는 1), 2)에 대한 일들을 하면서 보내고, 남은 5~10%는 4)의 일을 하는 것 같다.
저 4가지 이슈들에 대한 논문들은 정말 많은데 차차 정리해야겠다.
4. 기업의 AI 논문
1) 카카오브레인 논문 - www.kakaobrain.com/publication
카카오브레인
인간처럼 생각하고, 행동하는 지능을 통해 인류가 이제까지 풀지 못했던 난제에 도전합니다.
www.kakaobrain.com
2) SKT 브레인 논문 - www.skt.ai/index.do
SK Telecom AI Center
T-Brain, as a pioneer in the field of AI research, performs a pivotal role within AIC. We self-define the issues around AI and to solve these, research scientists and engineers across different expertise, from deep learning algorithm and techniques to sign
www.skt.ai
3) 네이버 클로바 논문 - clova-ai.blog/publication-list/
Publication List
Visit the post for more.
clova-ai.blog
5. 논문은 아니지만 유용한 기술 블로그
단비 | NC 공식 블로그
blog.ncsoft.com
NCSOFT DANBI
danbi-ncsoft.github.io
Blog - LINE ENGINEERING
#diagram #documentation #Technical writing
engineering.linecorp.com
카카오엔터프라이즈 기술블로그 Tech&(테크앤)
카카오엔터프라이즈의 기술블로그, Tech&(테크앤)입니다.
tech.kakaoenterprise.com
쿠팡 기술블로그 — Coupang Technology Blog – Medium
쿠팡 기술블로그 입니다. 쿠팡의 기술을 통한 혁신 스토리와 개발자 문화를 공유합니다.
medium.com
Airbnb Engineering & Data Science – Medium
Creative engineers and data scientists building a world where you can belong anywhere. http://airbnb.io.
medium.com
Netflix TechBlog
Learn about Netflix’s world class engineering efforts, company culture, product developments and more.
netflixtechblog.com
티스토리라서 그런가.. 네이버 d2 url이 추가 안 된다.
naver d2 d2.naver.com/home도 공부할 때 좋은 자료가 많은 것 같다.
머신러닝, 딥러닝을 공부하는 학생입니다.
잘못된 부분이나, 추가할 부분이 있다면 자유롭게 댓글 남겨주세요.
@sohyunwriter
'Artificial Intelligence' 카테고리의 다른 글
| [AI] epoch, batch size, iteration, step (0) | 2021.02.21 |
|---|---|
| ML 관련 Top-tier 학회 명단 (0) | 2021.02.11 |
| 영어 변수명 및 약자 (0) | 2021.01.25 |
| One Hot Encoding의 의미와 필요성 (0) | 2021.01.19 |
| train data / validation data / test data 차이 (0) | 2021.01.19 |